- Inspired by the animal/human visual system
- Primarily created to handle visual recognition but has since found wider applications.
Key Features of a CNN Architecture
- Each unit, or neuron, is dedicated to its own receptive field. Thus, every unit is meant to ignore everything other than what is found in its own receptive field.
- The receptive field of each neuron is almost identical in shape and size.
- The subsequent layers compute the statistical aggregate of the previous layers of units. This is analogous to the 'pooling layer' in a typical CNN.
- Inference or the perception of the image happens at various levels of abstraction. The first layer pulls out raw features, subsequent layers pull out higher-level features based on the previous features and so on. Finally, the network gets an overall perception of an image in the last layer.
Components of a CNN
VGGNet is a pure implementation of a CNN.
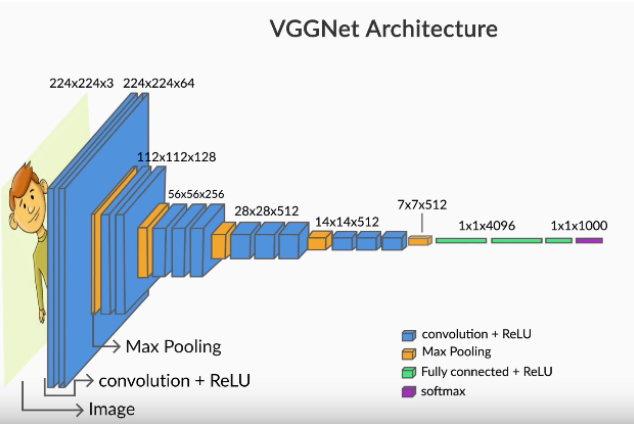
- Convolution
- Pooling Layers
- Feature Maps
Convolution
- Process of applying a filter on an image to get a specific, specialised perspective of the image.
- A filter is a somewhat arbitrary matrix of numbers, which is smaller than the image matrix
- The filter is applied or scanned on the entire image.
- The convolution process essentially does an element-wise multiplication between the image pixel numbers and the filter numbers and sums them up.
- Hence a 6x6 image when convolved with a 3x3 filter will yield a 4x4 matrix since the filter can be placed in 4 different horizontal & vertical positions each on the original image.
Padding Calculation to maintain post-convolution input size
The output size is . With p=1, k=3, s=1, the output will always be (n, n).
No comments:
Post a Comment